


...in 10 minutes
The beginnings of Big Data
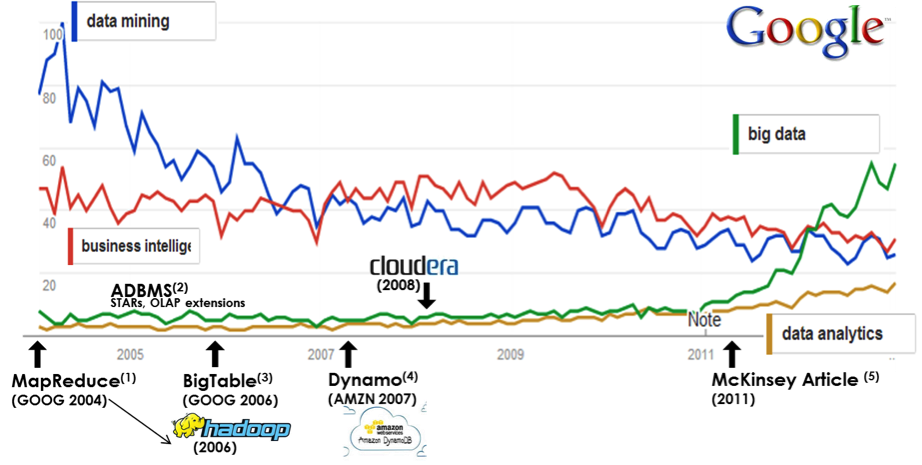
MapReduce (Dean and Ghemawat) | BigTable (Chang et.al.) | DynamoDB (DeCandia et.al.) | McKinsey whitepaper
Hadoop is
- A NOSQL platform
- An open-source Apache project implementing the 2004 MapReduce paper
- Written in Java, with Java and streaming API
- Designed for use on commodity hardware (e.g. racks of Dells, Amazon EC2) and scalable to thousands of nodes, although most clusters are tens of nodes
- The name of Doug Cutting's son's toy elephant
Aside: Not Only SQL
- Is for storing images, multimedia, objects of varying size
- Some database-style options:
 ,
,

- Some key, value pair options:
 ,
,

Aside: Big Data
- Tweets that appear faster than MySQL can create keys
- Data that exceed supported table dimensions
- e.g. columns as positions in the human genome
- e.g. rows as items on the receipt of every Walmart transaction in a year
- multimedia, sparse tables, or huge variations in object size
Hadoop architecture is
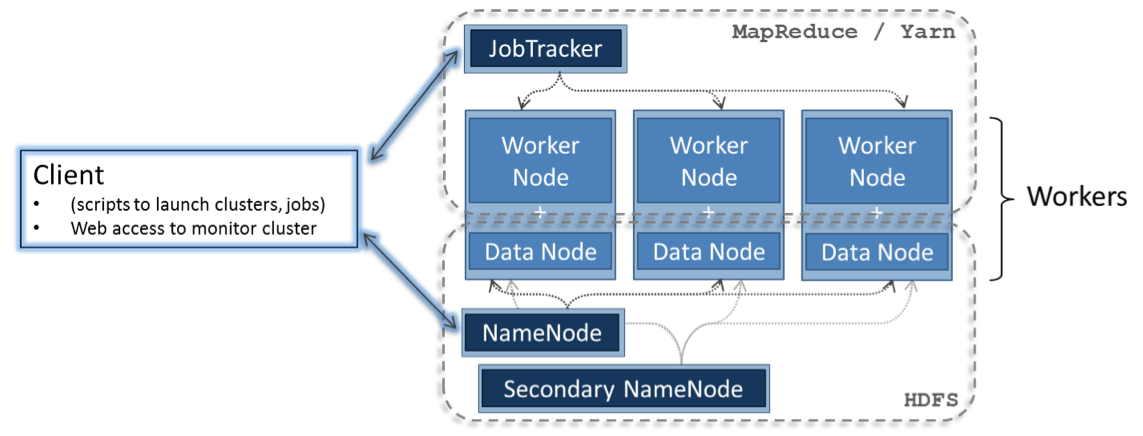
- A distributed file system
- A distributed compute system
Hadoop architecture is
- A distributed file system
- A distributed compute system
Hadoop architecture is
- A distributed file system
- A distributed compute system
These are the individual machines
(But all of the Hadoop jobs can run on one computer / VM for debugging and development.)
- One master for the HDFS, one for MapReduce jobs
- Secondary master
- Multiple workers
The individual machines
(But all of the Hadoop jobs can run on one computer / VM for debugging and development.)
- One master for the HDFS, one for MapReduce jobs
- Secondary master
- Multiple workers
The individual machines
(But all of the Hadoop jobs can run on one computer / VM for debugging and development.)
- One master for the HDFS, one for MapReduce jobs
- Secondary master
- Multiple workers
MapReduce




Problem: want pizza
But we're broke ⇒ must count our change- Map step
- Everyone empty their pockets; bring the change to the front table
- Shuffle Sort step
- I (the Master) will group coins by denomination
- Reduce step
- Everyone count a pile
- End
- Ask everyone for their result and sum

So what?
every variable imaginable for every customer
=
Target identifies a pregnant teen by her purchase behavior before her dad knows
...enter Mahout (2011)

Mahout is a Machine Learning and parallel linear algebra library that has a Spark + Scala shell implementing the distributed matrix libraries only (with plans for the rest). Written in Java.
...and Yarn (MapReduce 2 — 2012)
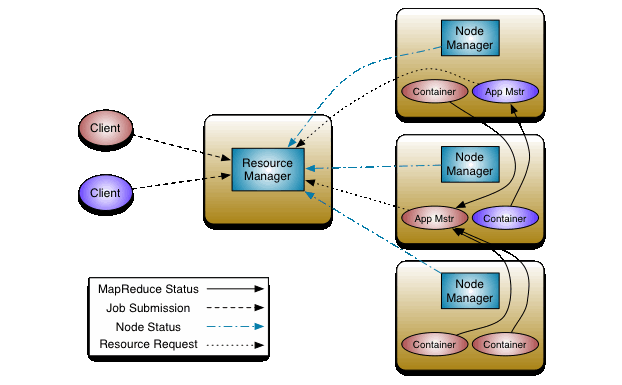
MapReduce is painfully slow and inflexible; MapReduce 2 splits the JobTracker to two processes, broadens the API, and gives the user more control over how the jobs execute.
...and Spark (2014)

Speed wins: Mahout announced near the end of last year that it
will stop developing for MapReduce and will exclusively write
code for use with Spark.
No wonder when looking at the performance:
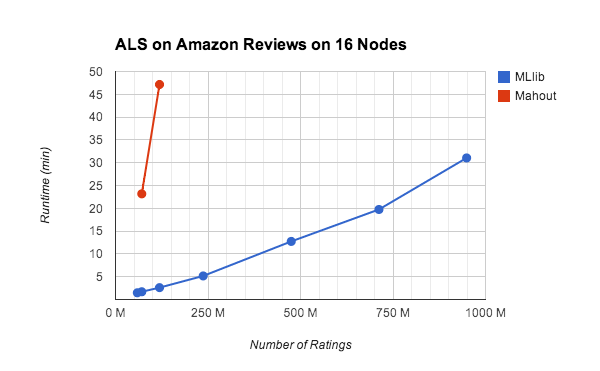
MLib is part of Spark; ALS is a machine learning algorithm.
blog post with benchmark